Seleniumを使ったテストで鬱陶しいことのひとつ、
ブラウザのバージョンとWebDriverのバージョンが違うことによるエラー
これを解消します!
前置きなどをすっ飛ばして自動で取得するやり方を見たい場合はここまでスキップ
目次
WebDriverのバージョン違いエラーとは
例えば下記のようなエラー
selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 96
Current browser version is 99.0.4844.51 with binary path C:\Program Files\Google\Chrome\Application\chrome.exe「selenium.common.exceptions.SessionNotCreatedException」はChromeブラウザとWebDriverのバージョンが一致しないときに出る例外で、後続のエラーメッセージでバージョンの差異を確認できる
This version of ChromeDriver only supports Chrome version 〇〇
┗WebDriverがサポートしているChromeブラウザのバージョン
Current browser version is 〇〇
┗起動しようとしたChromeブラウザのバージョン
手動でWebDriverを入手
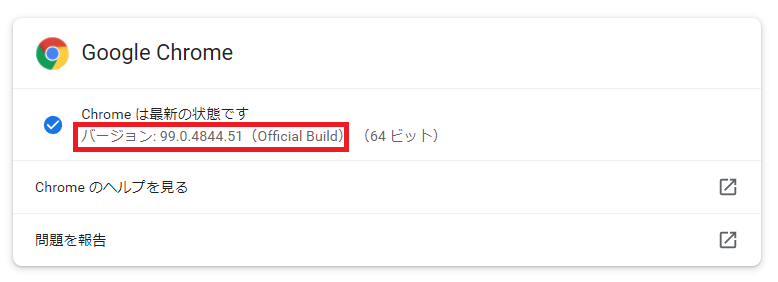
Chromeブラウザのバージョンを確認
chrome://settings/help をブラウザで開くことでChromeのバージョンを確認します。
WebDrvierをサイトからダウンロード
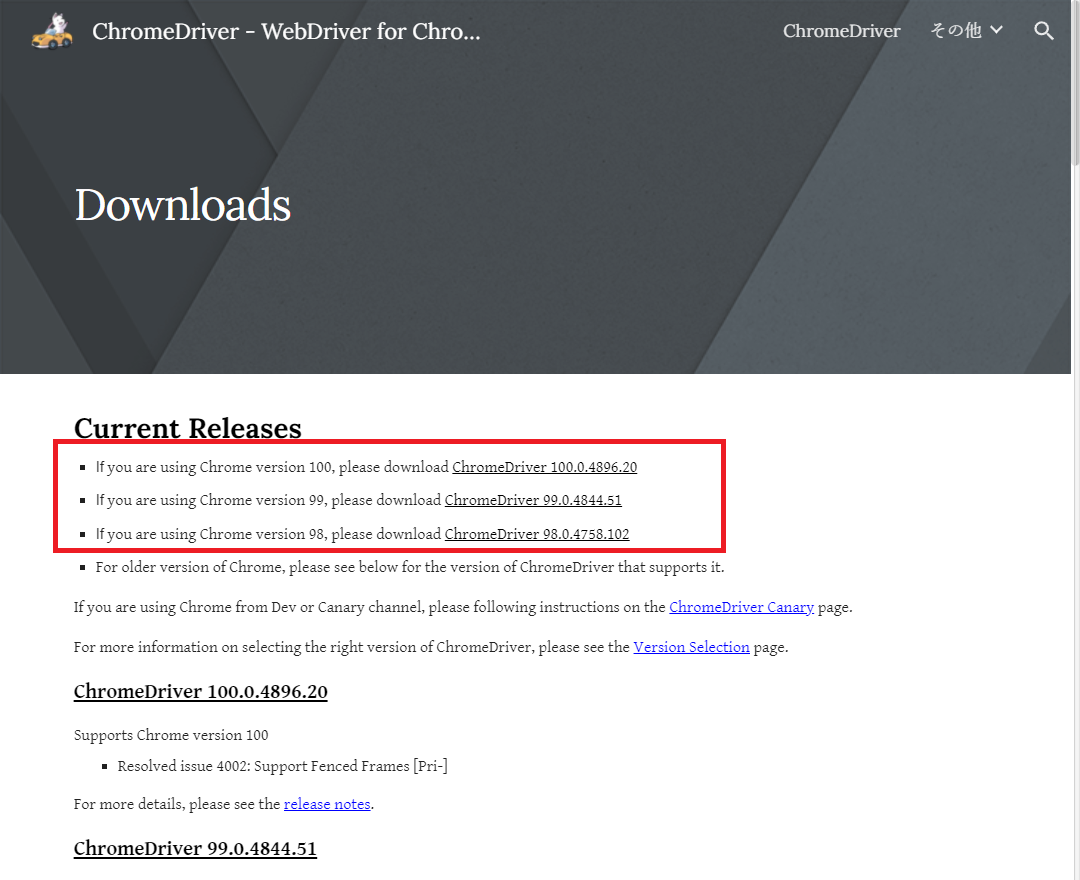
https://chromedriver.chromium.org/downloads にアクセスし、Current Releasesの項目を確認します。
先ほど確認したブラウザのバージョンと一致したリンクをクリックします。
※メジャーバージョンが一致すれば端数のバージョンは必ずしも同じでなくてOK
リンクをクリックするると下記のようなページにジャンプするので、自身の環境にあったzipファイルをダウンロードします。
※Windowsの場合はchromedriver_win32.zip
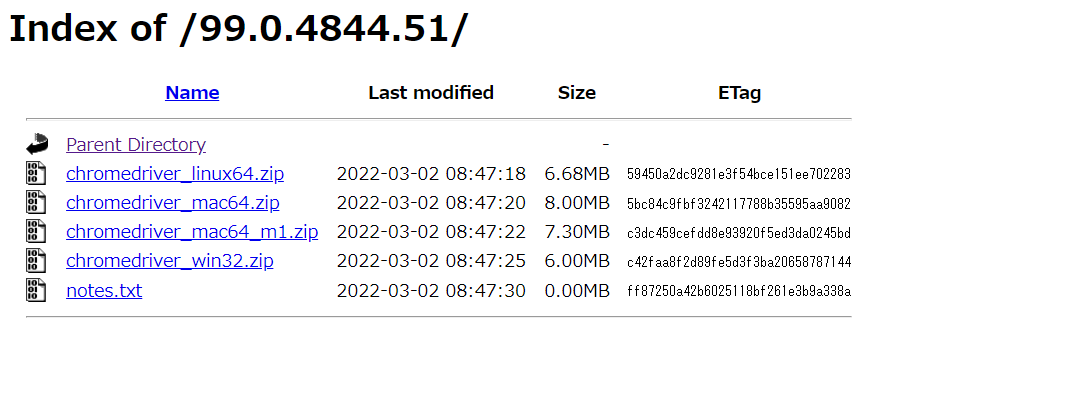
WebDriverの配備
あとはPythonで呼び出せるよう適当なフォルダにwebdriverを配備して完了!
自動でWebDriverを入手
Pythonで必要とあらば自動ダウンロードするように記述
でも手動でいちいちダウンロードするのは手間ですよね・・・?
ということでWebDriverがもし古かったり、存在しなかった場合、自動で上記のサイトに適当なWebDriverをダウンロードし、プログラムを継続するようにしたしていきます。
手順としては下記の通り。
- ソースコードをコピペ
- コンソールで「pip install lxml」を実行し必要なライブラリを導入
- Shift+F10で実行
ソースコード
import os
import re
import shutil
import zipfile
from pip._vendor import requests
from selenium import webdriver
from selenium.webdriver.chrome import service as cs
from selenium.common.exceptions import SessionNotCreatedException
from bs4 import BeautifulSoup
webdriver_url = "https://chromedriver.storage.googleapis.com/" #ウェブドライバーページ
file_name = "chromedriver_win32.zip" #Windows用のファイル名
chrome_service = cs.Service(executable_path=os.getcwd() + "\\webdriver\\chromedriver.exe")
# ChromeWebdriverファイルのパス指定
try:
if os.path.isfile(os.getcwd() + "\\webdriver\\chromedriver.exe")== False:
raise FileNotFoundError()
driver = webdriver.Chrome(service=chrome_service)
driver.close()
except (FileNotFoundError,SessionNotCreatedException) as e:
if type(e) == SessionNotCreatedException:
print("WebDriverファイルが古い可能性があります。最新バージョンのダウンロードを開始開始します。")
elif type(e)==FileNotFoundError:
print("WebDriverファイルが存在しません。ダウンロードを開始開始します。")
else:
print("不明な例外です。")
print(e)
exit()
response = requests.get(webdriver_url)
soup = BeautifulSoup(response.text,"lxml-xml")#lxmlのインストールが必要
if not os.path.exists(os.getcwd() + "\\webdriver\\tmp\\"):
os.makedirs(os.getcwd() + "\\webdriver\\tmp\\")
success_flg = False
version_arr ={}
cnt = 0
for version in reversed(soup.find_all("Key")):
cnt += 1
if file_name in version.text:
version_name = re.compile(r'/.*').sub("",version.text)
version_name = re.compile(r'\..*').sub("", version_name).zfill(5)+str(cnt).zfill(5)
version_arr[version_name] = version.text
for version in sorted(version_arr.items(),reverse=True):
zip_source = requests.get(webdriver_url+version[1])
print("起動テストを開始します\t"+webdriver_url+version[1])
# ダウンロードしたZIPファイルの書き出し
with open(os.getcwd() + "\\webdriver\\tmp\\" + file_name, "wb") as file:
for chunk in zip_source.iter_content():
file.write(chunk)
# ZIPファイルの解凍
with zipfile.ZipFile(os.getcwd() + "\\webdriver\\tmp\\" + file_name) as file:
file.extractall(os.getcwd() + "\\webdriver\\tmp\\")
try:
driver = webdriver.Chrome(executable_path=os.getcwd() + "\\webdriver\\tmp\\chromedriver.exe")
if(os.path.isfile(os.getcwd() + "\\webdriver\\chromedriver.exe")):
os.remove(os.getcwd() + "\\webdriver\\chromedriver.exe")
shutil.move(os.getcwd() + "\\webdriver\\tmp\\chromedriver.exe",os.getcwd() + "\\webdriver\\chromedriver.exe")
print("正常に起動しました。WebDriverを上書きします。")
shutil.rmtree(os.getcwd() + "\\webdriver\\tmp\\")
success_flg = True
break
except SessionNotCreatedException as e:
print("起動中にエラーが発生しました。\t"+webdriver_url+version[1])
#print(version_arr)
if not success_flg:
print("WebDriverファイルの上書き中に例外が発生しました。処理を中断します")
#▼以降にWebDriverの処理を記述。。。
print("Good Luck!!")バージョン情報XMLからWebDriverを探しに行くので、解析用にlxmlのインストールはPycharmのターミナルから行う
WebDriverファイルが存在しなかった場合
「FileNotFoundError」例外がraiseされ、
「WebDriverファイルが存在しません。ダウンロードを開始開始します。」
と出力してWebDriverのサイトからWebDriverファイルをダウンロードしに行きます。
WebDriverファイルが存在しないためにSeleniumでアクセスできず、「BeautifulSoup」を使って
ダウンロードするようにしています。
このときWebDriverのどのバージョンが必要であるかは正確にわからないので、
試しにSeleniumで呼出しを行い、WebDriverが古かった場合に出力される「SessionNotCreateException」が発生したらバージョンを下げたファイルでダウンロードし再度実行、、、というのを繰り返します。
WebDriverが古かった場合
にっくき「SessionNotCreatedException」が自動でraiseされ、
「WebDriverファイルが古い可能性があります。最新バージョンのダウンロードを開始開始します。」
と出力して、WebDriverファイルが存在しなかったときと同様の処理を行います。
まとめ
WebDriverが古い問題は、たまにSeleniumを実行しようと思うと頻繁に遭遇します。
ブラウザ操作を自動化したので、できればそのような問題も自動で整備したいもの、テストの度にダウンロードするのは、
かなり!
面倒なので、今後Seleniumを使うときは必ず実装しておきたい。
■2022.11.05
・lxmlのインストール手順追加
・WebDriverのバージョン検証をする順番を最適化